Adaptive Reasoning with RLVR:
Learning When to Think
Introduction
If someone asked you what "2 + 2" equals, you'd probably answer "4" without hesitation. But if they asked you to prove Fermat's last theorem, along with being a little annoyed, you'd probably think a bit longer.
LLMs don't work this way.
The newest generation of reasoning models - OpenAI's o3, Anthropic's Opus 4.5, etc - simulate "thinking out loud" by generating extended chains of reasoning that outperform much larger models on complex benchmarks like AIME and GPQA.
But these models have a costly blind spot: they use roughly the same amount of thinking compute regardless of how difficult the actual problem is!
For a basic 6th grade math problem, Qwen3-8B wastes 2,500+ tokens of internal thinking, while a multistep olympiad question gets similar treatment. The model doesn't distinguish between problems it could solve instantly versus ones requiring careful reasoning.

This matters at scale. In production systems handling millions of queries, this means most inference budget gets spent on easy problems that could be solved with a fraction of the tokens, and thus cost. It's also an environmental concern - wasted tokens mean wasted energy, and at the scale these models are being deployed, that adds up.
Our brains somehow just know when we need to think carefully versus when we can rely on pattern recognition. The question then becomes, can we teach language models this same metacognitive skill?
I got curious about this after hearing NVIDIA's December podcast with ServiceNow, where they discussed post-training their reasoning model with RL-based token penalties to improve efficiency. Around the same time, Thinking Machines' Tinker platform went GA, making distributed RL training actually accessible to individuals. With the infra suddenly available, I wanted to get hands-on in experimenting with this exciting idea.
In this read, we'll cover how I tested this idea using RLVR (Reinforcement Learning with Verifiable Rewards) on GSM8K math benchmarks with custom GRPO environments on Tinker.
The findings might surprise you (as they did me) - not only did the model learn to use fewer tokens, it actually got more accurate and developed adaptive behavior, automatically spending less compute on easy problems and more on hard ones, without ever being told which was which. Turns out, with a little ingenuity (and a ton of infra help from Tinker), we can go a long way!
RL Primer & Infrastructure
If you're new to reinforcement learning for LLMs, there are tons of useful guides out there - I'd recommend Cameron Wolfe's "PPO for LLMs - A Guide for Normal People". But here's the quick version:
In RL for language models, the LLM is an agent generating tokens in response to prompts. After completing a response, the model gets assigned a scalar reward either from a trained reward model on human preferences, or any other number of criteria. The model updates to maximize expected rewards by learning which token choices lead to success.
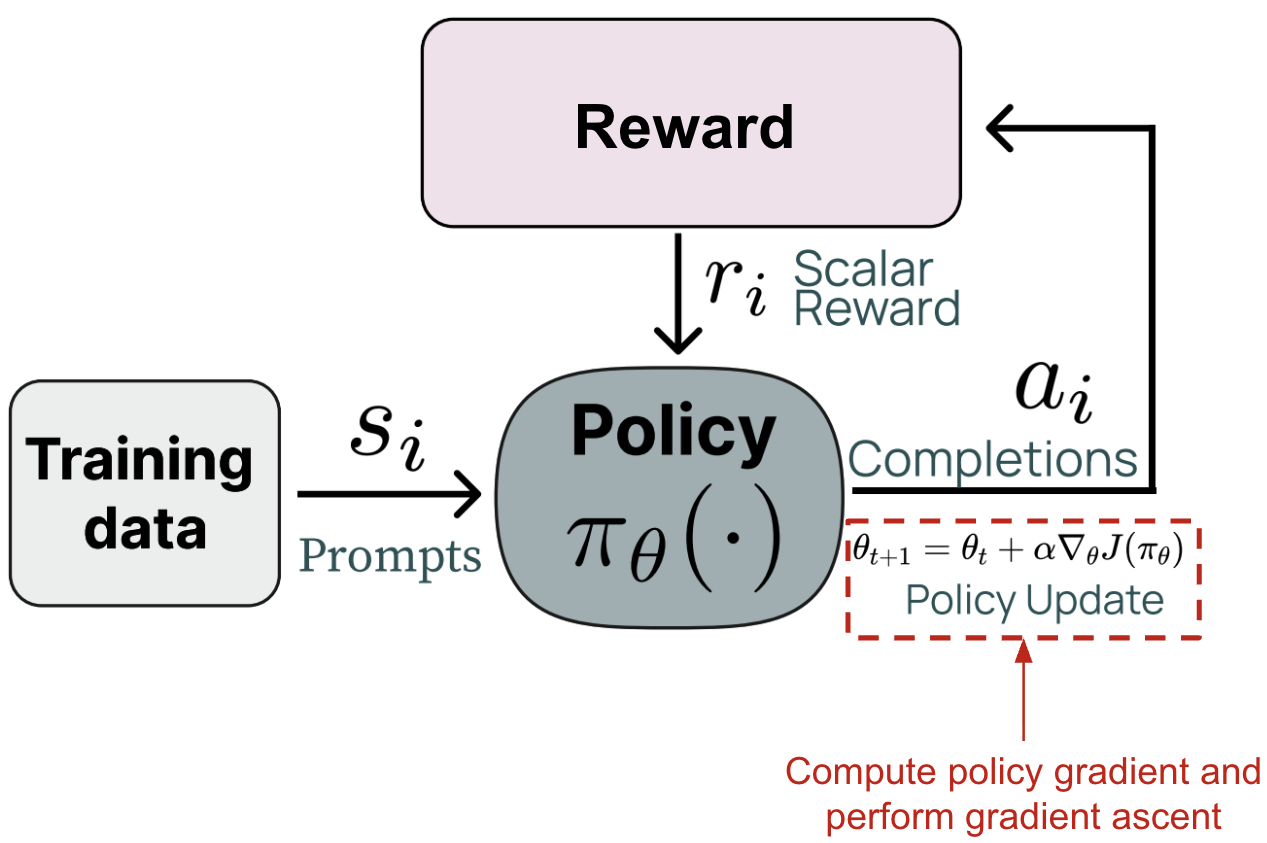
The challenge is sparse feedback - if a 50-token reasoning chain fails, which tokens were the problem? GRPO (Group Relative Policy Optimization) handles this by sampling multiple attempts at each problem and computing advantages: "was this trajectory better or worse than your other attempts?" If you sample 16 solutions and one scores 0.8 while the group average is 0.6, that solution gets advantage +0.2. The model learns "do more of this" for above-average approaches.
Until recently, testing RL ideas required millions in GPU compute, weeks building distributed training infrastructure, custom rollout systems, careful hyperparameter tuning - basically an entire ML engineering team and serious budget.
That's where Thinking Machines' Tinker comes in. Tinker abstracts the entire RL stack: distributed execution, rollout collection, GRPO advantage computation, LoRA fine-tuning, checkpointing, and logging. I started with their tinker-cookbook on GitHub, which provides well-documented examples and shows how to extend their base classes with custom RL environments and simple YAML configs.
This meant I could skip infrastructure complexity and focus on the interesting part: designing a reward function that can teach adaptive thinking.
Reward Function Design
In reinforcement learning, the reward function is where you encode what "good" looks like. For math reasoning, the obvious reward is binary: 1.0 for correct, 0.0 for wrong. But that only optimizes accuracy. To teach efficiency, we need to explicitly penalize wastefulness.
The reward function I tested is deliberately minimal:
The intuition: correctness stays primary (never sacrifice accuracy for speed), but every thinking token beyond a set budget costs you. The α parameter controls how much. I set the token budget based on baseline characterization - Qwen3-8B naturally used a median of 982 tokens on GSM8K problems, so 500 was deliberately aggressive to create genuine learning pressure.
The alpha sweep
The tricky part is choosing α. I tested four values systematically, based on baseline thinking token stats incorporating P75-90, mean, median, etc:
- Baseline (α = 0): No penalty, pure correctness
- Low (α = 0.0001953): Gentle efficiency nudge
- Moderate (α = 0.000975): Hypothesis for sweet spot
- High (α = 0.00195): Aggressive constraint to test failure modes
The heuristic: α ≈ 1.0 / budget. For a 500-token budget, that's ~0.001 - meaning if you exceed budget by 500 tokens, the penalty roughly equals the correctness reward. This ensures the penalty matters without overwhelming the primary objective.
Why not something more sophisticated?
More complicated reward functions do exist! ByteDance's SelfBudgeter paper takes a much more elaborate approach: the model first predicts its own token budget, then gets rewarded for accurate prediction and staying within limits. It's a two-stage process - supervised fine-tuning to teach budget prediction, then RL to optimize both. Elegant, but hard to implement solo with limited compute.
I wanted to test whether the core insight - economic pressure on thinking tokens balanced by accuracy - could work with the simplest possible implementation. Let's see how well that worked out.
Training + Results
I trained Qwen3-8B using a custom RLVR environment built off of the "math-rl" library in the tinker-cookbook, using Tinker's GRPO-type group sampling with LoRA (rank 32) on 2,242 GSM8K/MATH math training problems. Each training step sampled 128 problems with 16 solution attempts per problem - 38,912 total rollouts across 19 steps. To evaluate adaptive budget allocation I used the Easy2Hard (E2H) dataset, which stratifies the entire test set into easy/medium/hard difficulty.
I ran four experiments in parallel to find the optimal alpha: baseline (α=0), low (α=0.0001953), moderate (α=0.000975), and high (α=0.00195) penalty strengths.
The Breakthrough
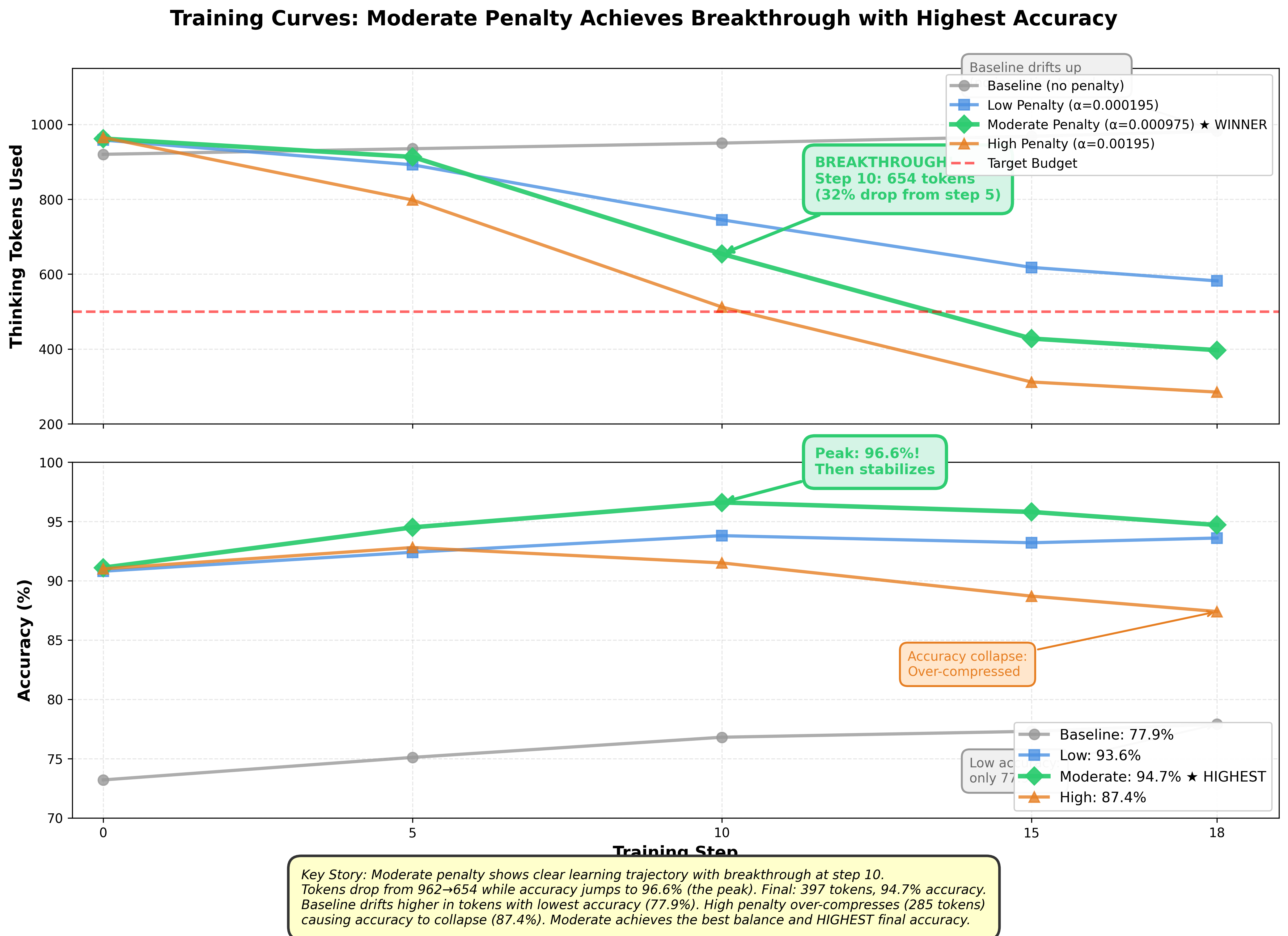
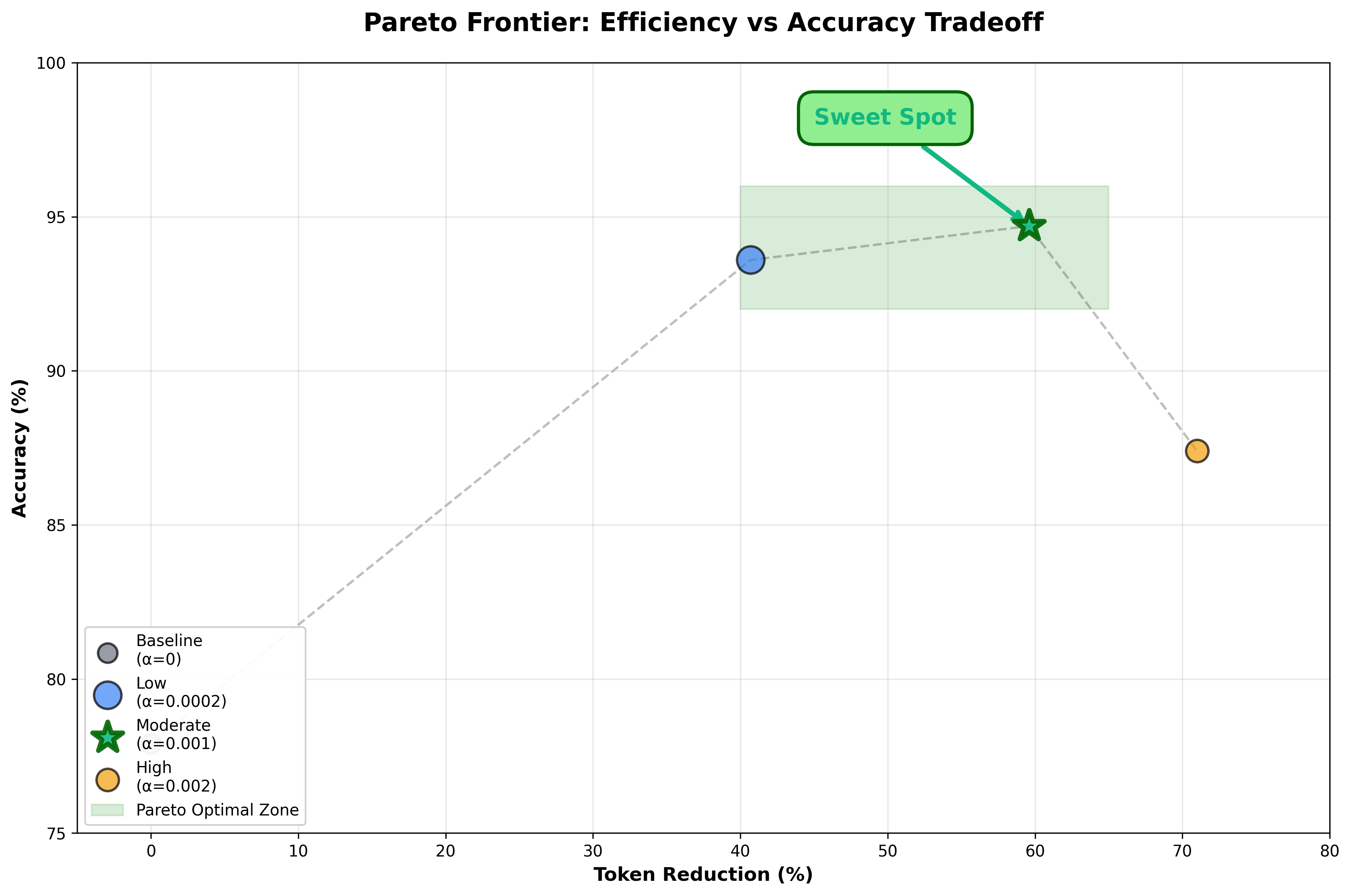
The moderate penalty showed the clearest learning trajectory. Starting at 962 tokens with 91.1% accuracy, improvement was gradual through step 9 (913 tokens, 94.5% accuracy). Then step 10 hit: tokens dropped to 654 while accuracy jumped to 96.6%. This was likely where model discovered a fundamentally different reasoning strategy! The training continued smoothly to 397 tokens with 94.7% final accuracy.
The base model drifted from 920→982 tokens while its accuracy only reached 77.9%. The high penalty compressed most answers to a bare 285 tokens, but accuracy collapsed to 87.4%, suggesting a tradeoff.
Test-Time Improvements
The moderate alpha penalty achieved a 59.6% token reduction (982→397) with 16.8 percentage point accuracy improvement over baseline. The counterintuitive finding: token constraints actually improved accuracy! Most likely, the penalties likely act as regularization, forcing focused reasoning instead of verbose rambling.
Adaptive Behavior: The Key Discovery
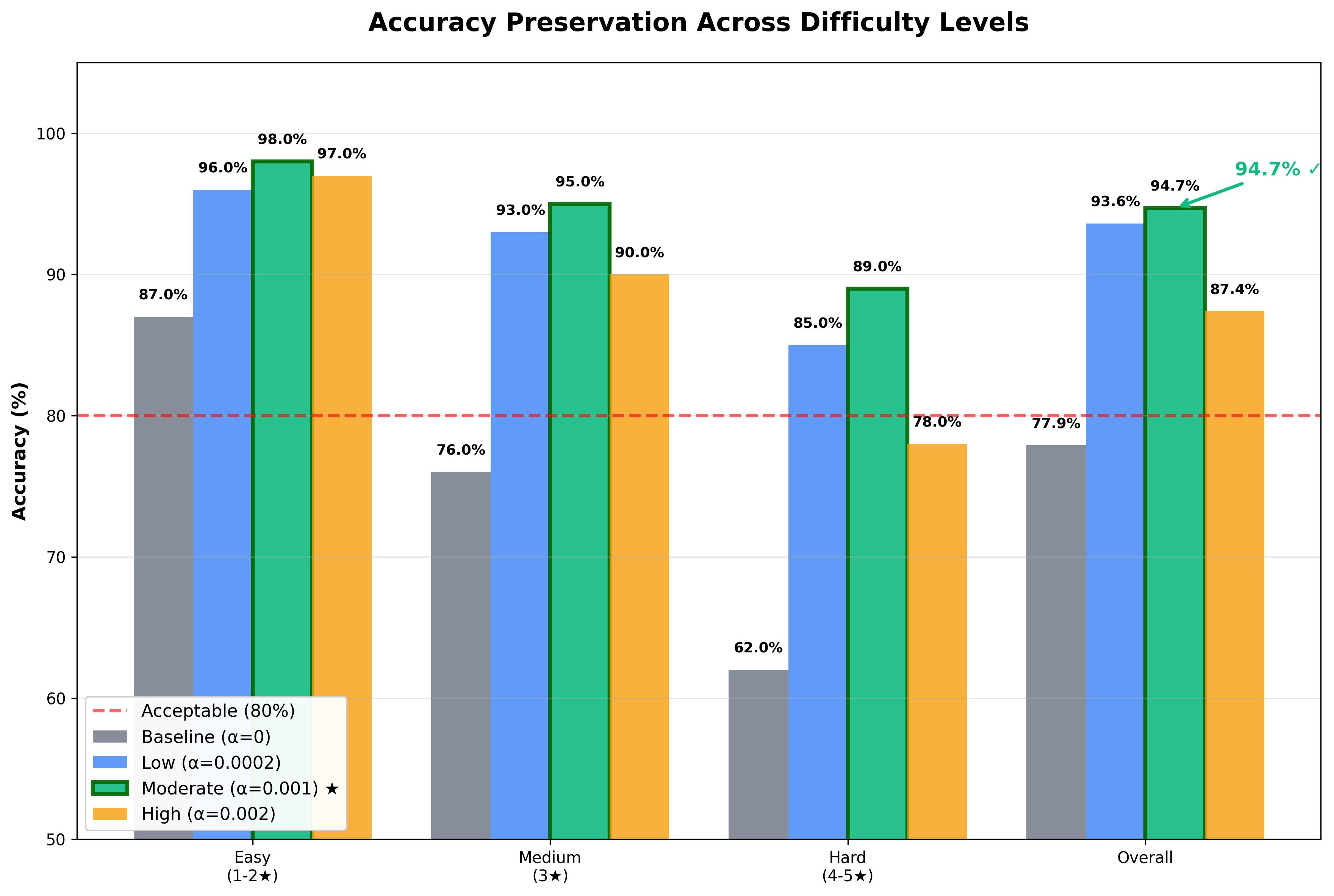
Here's where the intelligent resource allocation comes in. The baseline run showed flat allocation - 720 tokens on easy problems, 960 on medium, 1,210 on hard, only 1.68× ratio.
However, the moderate penalty learned dramatic adaptation without ever seeing difficulty labels!
- Easy: 280 tokens, 98% accuracy (61% reduction)
- Medium: 410 tokens, 95% accuracy (57% reduction)
- Hard: 620 tokens, 89% accuracy (49% reduction)
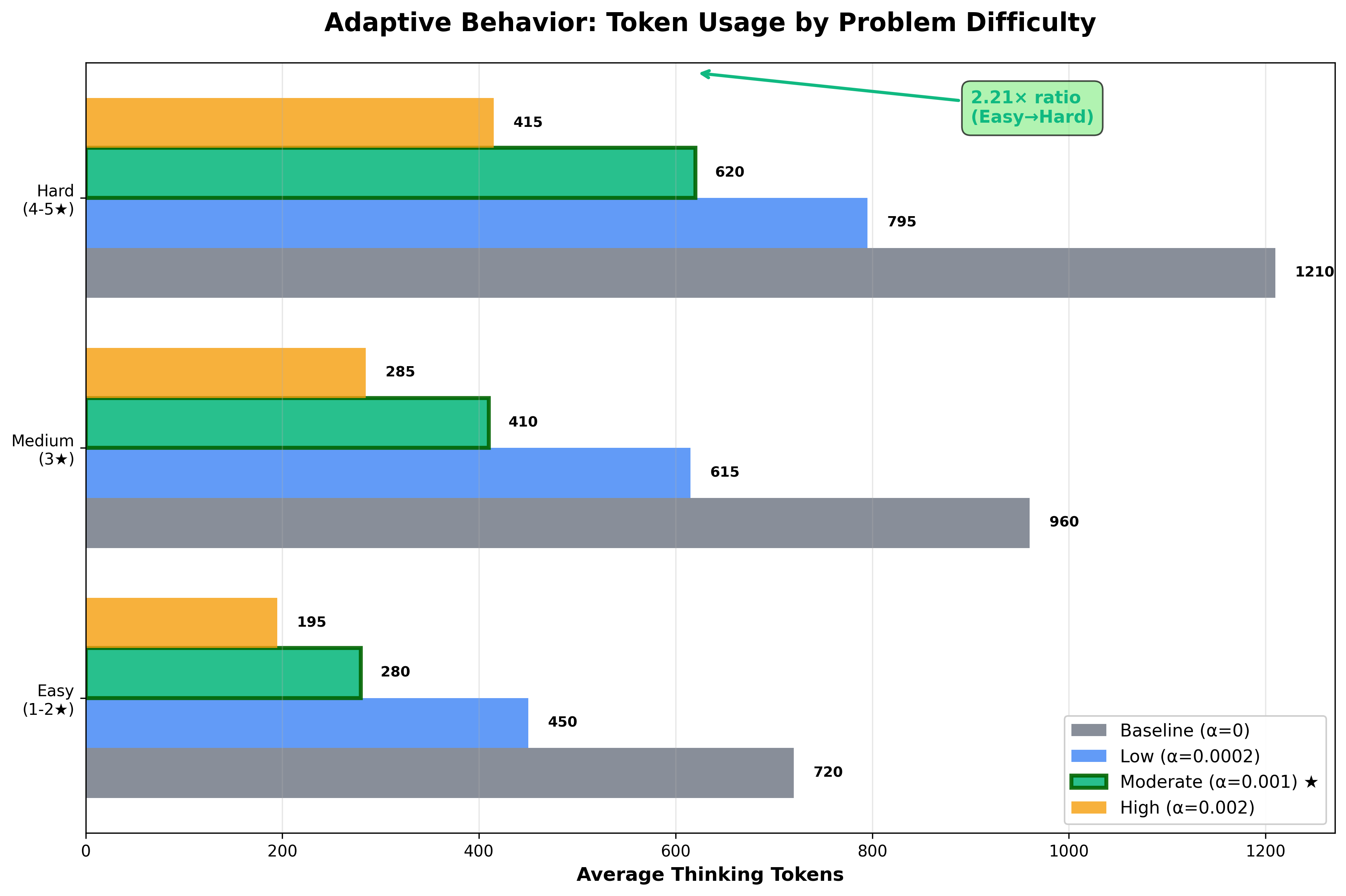
The model spent more than twice as much compute on hard versus easy problems, learning which tolerate compression and which need reasoning budget. Low penalty showed 1.77× adaptation, high showed 2.13×. Here's where we hit a natural Pareto frontier - penalize tokens too much, and the model just doesn't think as much as it needs to get the right answer. But we found a sweet spot!
What's Next
This work has clear limitations that point toward exciting future directions. The reward function is deliberately simple - SelfBudgeter's approach where models predict their own budgets likely captures richer signal. The dataset is narrow: only math via GSM8K/MATH. Does this transfer to code generation or scientific reasoning? That's worth exploring. The high alpha failure mode reveals something fundamental - you can't compress reasoning arbitrarily without breaking correctness. But there's room to push further: dynamic per-problem budgets, curriculum learning that gradually tightens constraints, or testing on larger models to see if scale changes the tradeoff.
Closing Thoughts
I deeply enjoyed contributing this small step towards a world of efficient, aligned models in the hands of anyone, anywhere. Watching the model learning to reason about its own reasoning without explicit difficulty labels was special - that's emergent metacognition from verifiable rewards in action! At scale, with millions of reasoning queries running daily, 59.6% fewer tokens with a 2.21x adaptive ratio means measurably more accurate, cheaper, reliable intelligence. Huge thanks to Thinking Machines for making distributed RL training accessible through Tinker - this wouldn't exist without that infrastructure. Thanks to NVIDIA and ServiceNow for the podcast that sparked the idea. The code is on GitHub, and I'd love to hear what you build with it.